Testing Scagnostic Rescaling Across Preprocessing Settings
scagnostics
cassowaryr
shape-analysis
simulation
R
Exploring whether fitted 95th percentile noise models for scagnostic indices remain valid when cassowaryr preprocessing choices change.
Published
19 May 2026
Exploring Whether One Fitted Noise Model Is Enough Across Different Preprocessing Settings
In this blog post, I explore whether a single fitted model is sufficient for rescaling scagnostic indices under different preprocessing settings. I use the cassowaryr package to calculate scagnostics, which are useful for shape analysis and for identifying different types of structure in two-dimensional projections.
Previously, I ran my simulations using the CRAN version of cassowaryr, version 2.0.2. At that time, the preprocessing steps were different from the current GitHub version. In particular, the simulations were run without hexagonal binning, and outlier removal was implemented as a one-time preprocessing step. My estimated noise distributions, and therefore the fitted models I used for rescaling, were based on those preprocessing choices.
However, the current GitHub version of cassowaryr has changed. Hexagonal binning has been added, and outlier removal is now implemented iteratively rather than using the previous one-step approach. These changes matter because the 95th percentile of the noise distribution depends on the preprocessing applied before calculating the scagnostic indices.
The reason I estimate the 95th percentile of the noise distribution is to rescale the scagnostic indices. In theory, the lower bound of a scagnostic index should be zero. However, for bivariate Gaussian noise, where there is no meaningful visual pattern, the raw scagnostic values do not necessarily reach zero. Therefore, I use the estimated 95th percentile of the noise distribution as a reference point for rescaling. This allows the indices to be placed on a more comparable scale, especially when they are used in higher-dimensional projection pursuit.
In my previous work, I estimated these 95th percentile values for several sample sizes and fitted a model using the CRAN version of cassowaryr. Later, when I wanted to implement my own changes to the package and submit a pull request, I noticed that the preprocessing steps in the GitHub version had changed. This raised an important question:
Can the fitted model from the previous preprocessing setup still be used under the new preprocessing settings?
To investigate this, I tested whether the old fitted model still controlled the upper tail of the noise distribution. In particular, I counted how often noise-generated scagnostic values exceeded the fitted 95th percentile threshold. If the model worked well across all preprocessing settings, then I would expect roughly 5% of the simulated noise values to exceed the threshold.
However, this was not what I observed. The exceedance rate was not consistently close to 5% across the different combinations of hexagonal binning and outlier removal.
Because of this, I decided to rerun the simulations using the current GitHub version of cassowaryr, starting with the setting hex = FALSE and out_rm = FALSE. This is important because, in the previous CRAN version, “no outlier removal” was not the default behaviour in the same way, and the outlier removal method itself was different.
My goal is to write a general simulation workflow that is not hard-coded for only one index or one specific set of parameters. I want the same code structure to be reusable for other scagnostic indices, sample sizes, preprocessing options, and simulation settings. This will make it easier to compare noise distributions across different versions of the package and across different preprocessing choices.
In the next section, I describe the general simulation code I used to generate the noise distributions and estimate the 95th percentile values.
General simulation function for estimating the 95th percentile of noise
To make the simulation process reusable, I wrote a general function called estimate_95th(). The purpose of this function is to estimate the 95th percentile of the noise distribution for one or more scagnostic indices.
The function is general in several ways. First, it can take a list of different scagnostic functions. Second, it can run the same index under different preprocessing settings, such as hexagonal binning and outlier removal. Third, it can be used over a sequence of sample sizes. Finally, it can save intermediate results to a CSV file, which is useful because these simulations can take a long time to run.
In each simulation, I generate bivariate Gaussian noise. Since this type of data does not contain a meaningful visual pattern, it provides a useful baseline for understanding how large a scagnostic value can be under noise alone. For each sample size, preprocessing setting, and index, I repeat the simulation many times and estimate the empirical 95th percentile of the resulting noise values.
Code
# General simulation function for estimating 95th percentile of noise estimate_95th <-function( index_funs, n_sim, n_start, n_end,step =25,settings =list(default =list()),seed =1028,workers =1,output_file =NULL,index_args =list(), ...) { extra_args <-list(...)if (is.function(index_funs)) {stop("Please provide index_funs as a named list, e.g. list(stringy05 = cassowaryr::sc_stringy05)") }if (is.null(names(index_funs)) ||any(names(index_funs) =="")) {stop("index_funs must be a named list.") }if (is.null(names(settings)) ||any(names(settings) =="")) {stop("settings must be a named list.") } sample_sizes <-seq(n_start, n_end, by = step)if (workers >1) {with(future::plan(future::multisession, workers = workers), local =TRUE) } else {with(future::plan(future::sequential), local =TRUE) }if (!is.null(output_file)) { readr::write_csv(tibble(sample_size =numeric(),setting =character(),index =character(),p95 =numeric(),n_valid =numeric(),n_sim =numeric() ), output_file ) } final_results <-list()for (n_obs in sample_sizes) {cat("Running sample size:", n_obs, "\n") raw_results <- furrr::future_map_dfr(seq_len(n_sim),function(i) { seed_i <- seed + i set.seed(seed_i) mat <-cbind(rnorm(n_obs),rnorm(n_obs) )map_dfr(names(settings), function(setting_name) { setting_args <- settings[[setting_name]]map_dfr(names(index_funs), function(index_name) { index_fun <- index_funs[[index_name]] all_args <-c( setting_args, extra_args, index_args[[index_name]] ) value <-tryCatch( {as.numeric(do.call( index_fun,c(list(mat[, 1], mat[, 2]), all_args) ) )[1] },error =function(e) NA )tibble(sample_size = n_obs,simulation = i,seed = seed_i,setting = setting_name,index = index_name,value = value ) }) }) },.options = furrr::furrr_options(seed =TRUE),.progress =TRUE ) p95_results <- raw_results |>group_by(sample_size, setting, index) |>summarise(p95 =as.numeric(quantile(value, 0.95, na.rm =TRUE)),n_valid =sum(!is.na(value)),n_sim = n_sim,.groups ="drop" )if (!is.null(output_file)) { readr::write_csv(p95_results, output_file, append =TRUE) } final_results[[as.character(n_obs)]] <- p95_resultscat("Finished sample size:", n_obs, "\n") }bind_rows(final_results)}
For the simulations in this analysis, I used a base seed of 1028. I ran 100000 simulations for sample sizes from 50 to 900. Because the simulations were computationally expensive, I saved the results in several smaller CSV files, each covering a different range of sample sizes.
Combining the simulation results
After running the simulations, I combined all of the CSV files into one dataset.
Once all the simulation results were combined, I fitted a model to describe how the estimated 95th percentile changes with sample size.
The fitted model uses the inverse square root of the sample size:
\[
p_{95}(n) = a + \frac{b}{\sqrt{n}}.
\]
This model is useful because the noise threshold usually decreases as the sample size increases. By fitting a smooth model, I can estimate the 95th percentile for different sample sizes without needing to rerun the full simulation every time.
If I want to fit the model only for a particular preprocessing setting, for example no hexagonal binning and no outlier removal, I can filter the results before fitting:
Then I fit the linear model separately for each scagnostic index:
Code
fit_results <- df_fit |>group_by(index) |>group_map(\(d, key) { fit <-lm(p95 ~ inv_sqrt_n, data = d)tibble(index =as.character(key$index),model ="a + b / sqrt(n)",a =unname(coef(fit)[1]),b =unname(coef(fit)[2]),r_squared =summary(fit)$r.squared ) }) |>bind_rows()fit_results
# A tibble: 2 × 5
index model a b r_squared
<chr> <chr> <dbl> <dbl> <dbl>
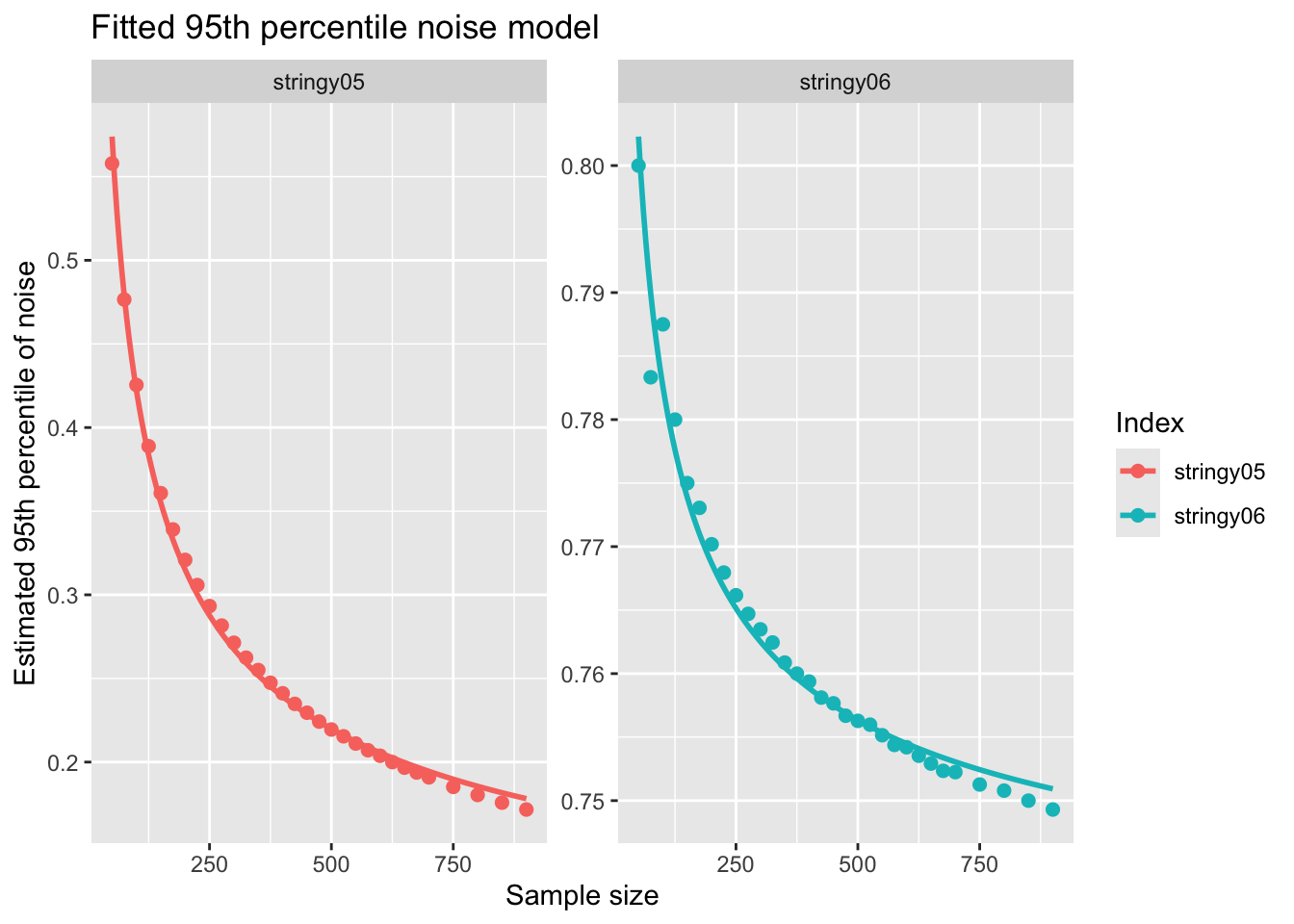
1 stringy05 a + b / sqrt(n) 0.0561 3.66 0.997
2 stringy06 a + b / sqrt(n) 0.735 0.475 0.977
The fitted coefficients can then be used to predict the 95th percentile noise threshold at any sample size:
Code
pred_data <-expand_grid(index =unique(df_fit$index),sample_size =seq(min(df_fit$sample_size),max(df_fit$sample_size),by =5 )) |>mutate(inv_sqrt_n =1/sqrt(sample_size) )pred_results <- pred_data |>left_join(fit_results, by ="index") |>mutate(fitted_p95 = a + b * inv_sqrt_n )
Finally, I plotted the observed simulation-based 95th percentiles together with the fitted model.
This fitted model gives approximation to the simulated 95th percentile values. I can then compare whether the same fitted model is valid across different preprocessing settings, such as with or without hexagonal binning and with or without outlier removal.
Code
stringy_500 <-read_csv("stringy_scale_500_10000.csv")stringy_500_rescaled <- stringy_500 |>left_join(fit_results, by ="index") |>mutate(sample_size = n_final,lb = a + b /sqrt(sample_size),rescaled_value = (value - lb) / (1- lb),rescaled_value =pmax(rescaled_value, 0) ) |>select(simulation:index , rescaled_value)
After fitting the inverse-square-root model to the estimated 95th percentiles, I checked whether the fitted threshold actually behaved like a 95th percentile. If the model were appropriate, approximately 5% of Gaussian noise simulations should exceed the fitted threshold. However, I observed exceedance rates larger than 5% in some cases. This suggests that the fitted model may be underestimating the empirical 95th percentile for some sample sizes or preprocessing settings. Therefore, the issue is not only the change in preprocessing; it may also be partly due to the fitted model not being flexible enough to capture the shape of the noise distribution across sample sizes.
Because of this, I decided to compare the original inverse-square-root model with several alternative models. The goal is to check whether a slightly more flexible model can better capture the shape of the simulated 95th percentile curve.
My original model was:
\[
p_{95}(n) = a + \frac{b}{\sqrt{n}}.
\]
This is simple and interpretable, but it may be too restrictive if the empirical 95th percentile curve bends more strongly for small or medium sample sizes. Therefore, I compare it with a few alternatives:
\[
p_{95}(n) = a + \frac{b}{\sqrt{n}} + \frac{c}{n},
\]
a log-quadratic model,
\[
p_{95}(n) = a + b \log(n) + c \log(n)^2,
\]
and natural spline models, which are more flexible.
If I want to focus on one preprocessing setting first, for example no hexagonal binning and no outlier removal, I can filter the data before fitting the models:
To compare the models, I calculate standard model summaries such as \(R^2\), adjusted \(R^2\), AIC, BIC, and residual standard error. I also compute RMSE directly from the fitted residuals.